
Computer Science
Introduction
I had little to no experience with computer science upon entering university. I thought it would be a lot of computer programming—and yes it is—but it is a lot more than just that. Computer science is about problem solving efficiently, and we program computers to help us with that.
After completing university I am hoping to get into software engineering or a related field.
Courses
- Intro to Computer Programming
- Intro to Computer Science
- Software Design
- Intro to the Theory of Computation
- Software Tools and Systems Programming
- Computer Organization
- Data Structures and Analysis
- Principles of Programming Languages
- Operating Systems
- Algorithm Design and Analysis
- Intro to Databases
- Principles of Computer Networks
- Computational Complexity and Computability
- Fundamentals of Robotics
- Intro to Artificial Intelligence
- Intro to Computer Vision and Image Understanding
- Intro to Machine Learning
Languages
- Python
- Java
- C
- C++
- MATLAB
- Racket
- Haskell
- RISC-V assembly
- LaTeX
Tools
- git
- Unix/Linux/MacOS/Windows
- Virtual Machines
- Microsoft Office
- Adobe Creative Cloud
Projects
Machine Learning Challenge: Predicting Food Items
Februrary 2025 — April 2025
In this project, I developed a supervised machine learning model to predict food items—Pizza, Shawarma, or Sushi—from survey data. This was one of the most hands-on and rewarding learning experiences I’ve had.
Problem Overview
The entire class completed a survey consisting of 8 questions about Pizza, Shawarma, and Sushi. Using this dataset of 1,644 responses (548 per food item), the goal was to build a machine learning model that could correctly classify the food based on survey answers.
Although the dataset was quite small, it was incredibly rich and diverse—each question captured a different aspect, from numerical and categorical attributes to textual responses. Specifically, the survey included questions about perceived complexity, ingredient count, serving setting, price expectations, associated movies, drink pairings, personal associations, and hot sauce preferences.
The teaching team also filled out the survey. The challenge was to build a model that generalizes well and performs best on their (unseen) responses.
Objective
The goal was to build a model that generalizes to unseen users. The focus was on real-world ML practices: robust data processing, careful feature engineering, fair evaluation, and avoiding data leakage.
Thoughtful Data Splitting
A major early decision I made was not to randomly split the data. Since each user had three responses, I insisted that the split must be person-based—ensuring no individual appears in more than one of the training, validation, or test sets. This was key to preventing data contamination and measuring generalization properly.
To support this, I implemented a two-stage data splitting strategy:
- Manual 70/15/15 ID-based split for manual exploration and tuning of hyperparameters along with visualization.
- GroupKFold cross-validation for more robust hyperparameter tuning and to maintain person-level separation across folds.
Feature Engineering
I designed and implemented a FeatureBuilder class. This modular pipeline handled:
- Text normalization and categorical mapping
- Missing value imputation (based only on training set statistics)
- Creating new features based on interactions (e.g., combining perceived complexity with hot sauce preference)
- Consistent transformation across all splits to prevent leakage and ensure fair evaluation
Each question (Q1–Q8) was processed with care. For textual features (movies, drinks, people), I experimented with several methods:
- Manual category mapping (e.g., top N drinks or movies)
- Binary Bag of Words
- Naive Bayes-based probability lookup: I trained a multinomial Naive Bayes model to compute the probability of each word indicating a food label. This allowed me to transform text into meaningful distributions over classes in a principled, data-driven way—without needing to pick arbitrary thresholds or categories. This also vastly reduced the number of features as compared to the Binary Bag of Words approach.
I also built a visualization pipeline to plot distributions (e.g., violin plots, box plots), compute feature statistics, and assess overlap between class distributions—helping me assess which features were most informative.
Model Exploration
To evaluate different modeling approaches, I created a flexible model evaluation framework and explored a wide range of models:
- k-Nearest Neighbors, Decision Trees, Logistic Regression, Multilayer Perceptrons (MLP), Naive Bayes, Random Forests, Extra Trees
In addition, I implemented many of these models from scratch.
Final Results
The best-performing model was an Extra Trees classifier with interaction features, which achieved over 90% accuracy on both the validation and test sets.
Report
The project culminated in a comprehensive LaTeX report (60 pages) documenting the entire pipeline—data processing, feature engineering, model experimentation, performance evaluation, and final decisions.
Reflections
This project was incredibly rewarding. It gave me a chance to deeply explore the full ML workflow—from raw survey data to polished predictions. I strengthened my understanding of model evaluation, data leakage, feature transformation, and ensemble methods. It also pushed me to think critically about fairness, generalization, and real-world deployment. It was a rewarding culmination of weeks of effort, and a clear example of hard work paying off.
Handwritten Digit Classification with k-NN
January 2025

In this project, I implemented a k-Nearest Neighbors (k-NN) classifier from scratch to classify handwritten digits from the MNIST dataset. The workflow began with storing the data in matrices and vectors, followed by splitting it into training, validation, and test sets.
I implemented functions to compute the squared Euclidean distance between an image and a set of images, leveraging NumPy’s vectorization and broadcasting for efficiency. By avoiding explicit loops and using np.argsort() for distance sorting, I was able to write compact and performant code for the k-NN algorithm.
I first evaluated the model’s accuracy across different values of k (from 1 to 10), achieving ~30% accuracy on the validation set. To improve performance, I normalized the dataset by subtracting the mean and dividing by the standard deviation of the training data—ensuring all pixel values were on a comparable scale. This simple preprocessing step boosted validation accuracy to over 90%.
Finally, I applied the optimal k value to the test set, achieving 90% accuracy, demonstrating the model’s ability to generalize effectively to unseen data.
Trading Strategy Development and Backtesting
December 2024
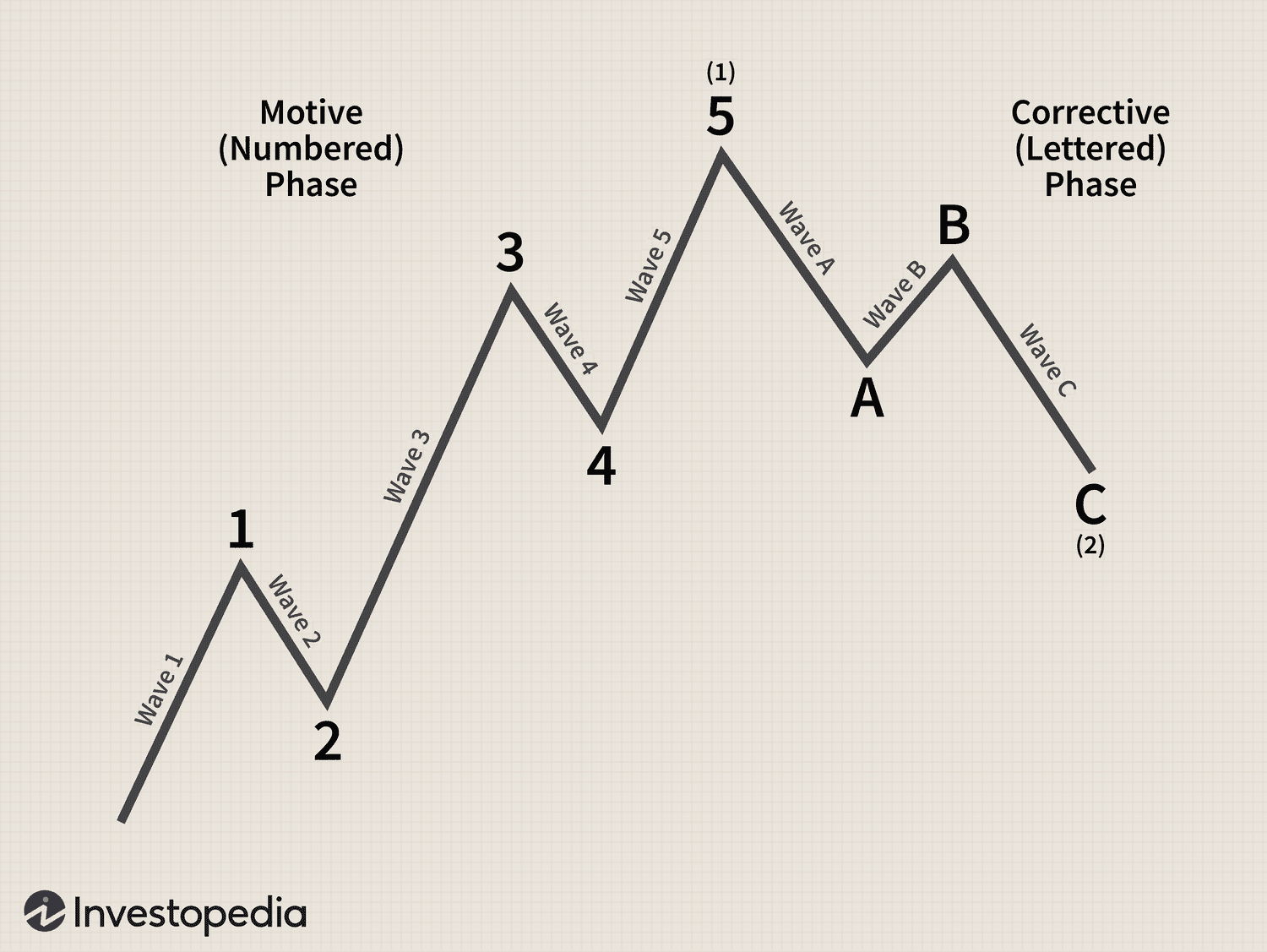
In this project, I developed my own trading strategy using Python and backtested it on assets such as the S&P 500 (SPX) and Bitcoin (BTC). My strategy incorporates technical analysis tools like the Elliott Wave Theory and Fibonacci retracements to predict market trends and identify entry/exit points.
The strategy focuses on detecting a 5-wave impulse pattern, followed by a 3-wave correction. I primarily analyze the 4-hour or daily time frames to identify the impulse and correction. Once a correction retraces between the 0.5 to 0.618 Fibonacci levels, I enter a long position, targeting a 1.318 to 1.618 extension of wave 1. The strategy is designed to trade the third wave, as it tends to be the most impulsive and significant in terms of price movement. I set the stop loss below wave 1 to minimize risk.
In addition to long positions, I apply a similar approach for short trades, looking for a 1-2 setup on the downside. This strategy has shown better performance compared to simpler strategies like moving average crossovers or overbought/oversold signals from RSI, as well as bullish and bearish divergences in RSI and MACD.
For future improvements, I plan to incorporate bullish and bearish divergences on the RSI to further confirm the strength of my long and short positions, enhancing the accuracy and reliability of the strategy.
For the backtest, I used historical price data from Yahoo Finance and Python’s backtesting libraries to simulate trades and evaluate performance metrics such as win rate, risk/reward ratio, and drawdown.
This project allowed me to deepen my understanding of algorithmic trading, refine my strategy, and improve my coding and analytical skills. I gained hands-on experience in both market analysis and backtesting.
Constraint Satisfaction: Battle Ship
Novemeber 2024
In this project, I tackled the Battleship Solitaire puzzle by formulating it as a constraint satisfaction problem (CSP). The puzzle presents a grid with hidden ships, and the goal is to deduce the locations and orientations of these ships based on given row and column constraints, as well as partial information about the ships (such as parts of ships already revealed). The puzzle is constrained by ship size, placement rules (ships cannot touch each other), and the number of ship parts in each row and column.
To solve the puzzle, I implemented a CSP solver using backtracking search along with techniques like forward checking and arc-consistency (AC-3) to propagate constraints efficiently. This process involved defining variables, constraints, and using heuristics to guide the search for solutions, ensuring that the ships are placed correctly according to the rules of the game.
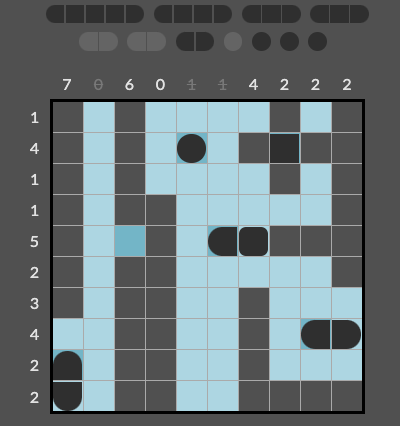
For this project, I opted for a ship-based approach instead of the typical cell-based one. This method minimizes the number of variables and constraints, better aligns with the game rules, and leads to more efficient constraint handling. It allowed me to capture the full complexity of the puzzle in a more intuitive and manageable way.
A significant portion of my time was dedicated to preprocessing the board to maximize available information before starting the main computation. By identifying water and ship parts early, I could systematically deduce the presence of complete ships, reducing ambiguity and streamlining the problem setup. This preprocessing step greatly enhanced the efficiency of the subsequent search process. I also optimized the constraint queue by prioritizing constraints based on a custom heuristic order, further accelerating the search. To further improve efficiency, I incorporated Generalized Arc Consistency (GAC) alongside the Minimum Remaining Values (MRV) heuristic. Additionally, I implemented a custom function to check for Domain WipeOut (DWO) scenarios before invoking GAC’s hasSupport() method, enabling the algorithm to detect invalid paths earlier and save significant computational time.
This project presented several challenges, requiring extensive troubleshooting and refinement to ensure the puzzle was solved the right way. While many would have chosen a simpler cell-based method, I was determined to tackle the more complex ship-based approach, even at the cost of a steeper learning curve. Ultimately, this approach paid off, enabling me to model the problem more accurately and efficiently. Despite the struggles, I am proud of the result and believe my implementation is one of the fastest and most efficient in my class.
Game Tree Search: Checkers
October 2024
In this project, I implemented an AI solver for Checkers endgames in Python using alpha-beta pruning. The solver navigates through the game tree, evaluating states to find optimal moves for both players. It handles simple moves, mandatory jumps, and multi-jumps, using an evaluation function and optimizations like node ordering and state caching to improve efficiency. The goal is to solve puzzles in the fewest moves while ensuring both players act optimally.

For the heuristic, I initially experimented with various approaches—such as distinguishing between kings and normal pieces, and analyzing piece layouts and patterns. However, the simplest heuristic, which evaluates the difference in piece count between player 1 and player 2, proved to be the most efficient and effective for endgames.
A key highlight of my implementation is the design of the generate_simple_successors() and generate_jump_successors() functions. These functions are written in a clean and efficient manner, adhering to the game’s movement rules. In generate_simple_successors(), I determine movement directions based on the type of piece, considering that normal pieces move forward diagonally, and kings can move in any diagonal direction. For generate_jump_successors(), I implemented an iterative approach with a stack to track multi-jump sequences, which avoids recursion and handles all jump scenarios, including mandatory and multi-jump cases.
To further optimize the Minimax algorithm, I implemented alpha-beta pruning with state caching using a transposition table. Additionally, I sped up the search process by sorting successor states based on their heuristic value before exploring them, maximizing pruning efficiency.
Overall, this project helped me gain a deeper understanding of game tree search algorithms while improving my ability to write clean, modular, and efficient Python code. The solver’s performance is efficient, even for complex endgame scenarios, and it adheres to the rules and complexities of Checkers gameplay.
State Space Search: Sliding Tile Puzzle
September 2024
For this project, I developed a solver for a sliding tile puzzle inspired by the classic game Hua Rong Dao. This involved implementing two search algorithms: Depth-First Search (DFS) and A* Search, both written in Python. The objective was to navigate a board of movable pieces to match a specified goal configuration.
One of the highlights of my implementation was the design of the heuristic function for the A* algorithm. Using Manhattan distance, I calculated the total distance each piece needed to move to its closest goal position. This heuristic was admissible (it never overestimated the cost), ensuring that the A* algorithm always found optimal solutions.
I also took special care in writing a clean and modular function for generating successor states. By leveraging a straightforward set of movement directions—[(0, 1), (0, -1), (1, 0), (-1, 0)]—I ensured that all valid moves were calculated efficiently while adhering to the rules of the game. This approach allowed for clear, maintainable code that accounted for each piece’s unique characteristics.
The program was designed to handle puzzles of varying complexity, from simple configurations to challenging ones. Each component, from parsing the input files to backtracking through the solution path, was tested and refined. I’m particularly proud of how well the program balanced performance and readability, solving even complex puzzles in seconds while maintaining clear and organized code.
This project not only deepened my understanding of state-space search algorithms but also honed my skills in writing modular, efficient Python code.

ext2 File System Commands
November 2022 — December 2022
In this project, I learned about the ext2 file system and implemented (in C) file system commands to operate on an ext2-formatted virtual disk.
The commands I implemented:
- mkdir (creating a directory)
- cp (copying a file)
- rm (removing a file)
- ln_hl (creating a hard link)
- ln_sl (creating a symbolic link)
Furthermore, I ensured that these commands are synchronized properly by guaranteeing mutual exclusion access to shared file system structures using mutexes.

Although these commands may seem simple and straightforward, in order to implement them for a particular file system is quite challenging. We need to work with binary data and need to have a good understanding of the file system that we are working with.
For example, say we have the following command: rm /folder/myfile. In the ext2 file system, every file and every directory corresponds to an inode. We would start at the root inode and search its data blocks (a linked list of directory entries) for an entry called “folder” and make sure that it is indeed a directory. Then we would search folder’s data blocks for an entry named “myfile” and make sure that it is indeed a file. Once all this has been verified, we can mark the inode and the data blocks (which hold actual file contents) for “myfile” as free so that they can be allocated by some other file or directory. Lastly, in the parent directory’s data blocks we need to reflect that “myfile” has been deleted by marking that entry as deleted in the linked list.
Page Tables and Replacement Algorithms
October 2022 — November 2022
Many students learn about page tables, address translation, and replacement algorithms. I got the opportunity to implement these ideas in practice. There were two parts to this project.
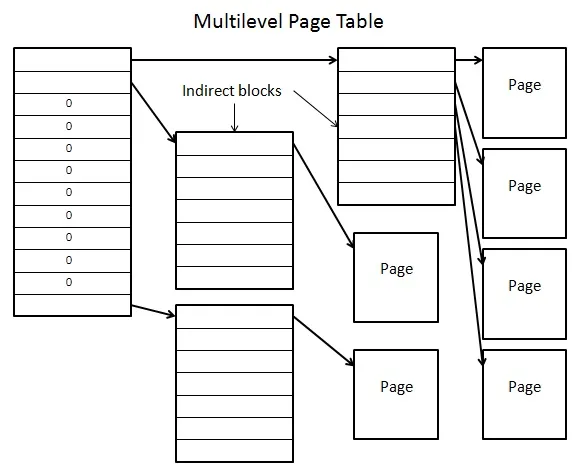
Part 1: Page Tables and Address Translation
In this task we are given virtual addresses and need to translate them into physical addresses using a three-level page table. This included bit manipulation and logical bitwise operations.
Basically, given a virtual address, we use some of the bits as an index into the first-level page table, some of the bits as an index into the second-level page table, some of the bits as an index into the third-level page table, and some of the bits as an entry offset. When we index into the first-level page table, we get a pointer to a second-level page table and when we index into the second-level page table, we get a pointer to the third-level page table. Then we use the offset to index into the third-level page table to retrieve our entry.
Part 2: Replacement Algorithms
In this task I implemented four different page replacement algorithms: FIFO, LRU, CLOCK, and ARC. Page replacement algorithms must be fast, hence I implemented these policies with efficiency in mind.
The idea behind replacement algorithms is that as pages are requested, memory will fill up. Once memory is full and a new page is requested, which old page do we evict to make room for the new requested page?
- The FIFO (first in, first out) page replacement algorithm evicts the oldest page in the cache.
- The LRU (least recently used) page replacement algorithm keeps tracks of recently used pages and evicts the page that has not been used the longest.
- The CLOCK page replacement algorithm is a low overhead approximation to the LRU algorithm. It does not keep track of the least recently used page. Instead, it evicts a page that “old enough” which is done using reference bits.
- The ARC page replacement algorithm is an advanced algorithm that keeps track of both recently used pages and frequently used pages plus a recent history of evictions. It is self-tuning, low-overhead, and scan-resistant that responds to changing patterns in memory accesses.
In the end, I also wrote a report in which I compared these replacement algorithms against each other by coming up with memory traces where one outperforms the other. I was able to observe the differences that a policy can make in practice.
Writing a Shell from Scratch
January 2022 — April 2022
In this project I wrote a C program that implemented a fully functional shell. This is the largest project I have worked on; it is also my proudest work.
Writing a shell from scratch is a large and daunting task, but I am glad I got the opportunity to experience it because I gained such a rich understanding of shells and Unix/Linux systems—which are widely used in industry today.

Features
My shell is called mysh and has the following features:
- builtin commands such as echo, wc, and cat. Since a shell has so many commands, if I did not create a builtin for a command, I ended up using bash shell’s implementation by forking a child process and using exec.
- supports storing an arbitrary number of environment variables by keeping track of them in a linked list data structure allocated on the heap.
- manages the file system by implementing builtin commands such as ls and cd.
- supports pipes and allows users to start processes in the background and foreground.
- keeps track of running processes in a linked list data structure allocated on the heap.
- ability to start a server in the background and listen for incoming messages. It can also send messages to other mysh instances with running servers.
Experience Gained
After completing this project I gained experience with
- Unix and Linux operating systems
- Common shell commands
- C programming
- Error checking and handling
- Dynamic memory allocation on the heap
- Working remotely on a different machine using ssh
- Implementing functionality on a tight weekly basis
- Writing well documented, organized, and extendable code
- Thoroughly testing and reasoning code separately before merging it with the main application
- git version control
- Creating unit tests using pyTest
SIMON Memory Game
February 2022—March 2022
In this project I programmed the famous SIMON Memory Game in RISC-V assembly.
I gained valuable hands on experience with assembly language after completing this project.
In class we learned about certain conventions that need to be followed when working in assembly. For instance, before jumping to a function call we need to save certain registers. I remember when I was working on the project, I encountered a super hard to find bug because I forgot to save the value in one of my registers and the function I was calling kept modifying its value.
I also learned about the programmer’s view of memory. This included learning about the stack and heap and how they grow towards each other. So when I was working on the project I had to keep in mind to lower (and not raise) the stack pointer when saving values.
This project made me appreciate the abstractions that exist today. We are lucky to have high level languages like Python and Java that do most of this super low level work for us.

Furthermore, I wrote an instruction manual for my game. This document concisely explains all the features of the game and walks one through on how to play the game. I put in a lot of effort into this document and thought the final product came out great.
Linear Algebra Calculator
January 2022
I participated in the PyJaC Rebooted Hackathon with two friends. All three of us have interest in math and find the field of linear algebra fascinating. So we decided to challenge ourselves to implement something we learned in class as a computer algorithm.
Our idea was to program a Linear Algebra Calculator in Python with two features:
- compute the determinant of a square matrix
- row reduce a rectangular matrix
We tried to optimize our algorithms. For instance, for the algorithm that computes the determinant of a matrix, our idea was to search for the row/column containing the most number of zeros before starting the cofactor expansion.
This was a cool experience where I got an opportunity to directly apply both my math and computer science knowledge to achieve a goal.

Three Musketeers Board Game
October 2021—December 2021
This project was broken up into three phases:
- Create a command-line interface version of the game using Java
- Create a graphical user interface version of the game using the JavaFX framework
- Work within a small team to improve code structure by recognizing common design patterns and by applying SOLID software design principles
There are two players: Guards and Musketeers. The Guards win if they manage to get all three Musketeers on the same row or column. The Musketeers win if they cannot capture any Guards (i.e. they cannot move) and if they are all not on the same row or column.
The game is playable in two modes:
- Player vs. Player
- Player vs. Computer (Random and Greedy strategies)

After completing this project, I gained valuable experience with
- designing heuristics for random and greedy strategies
- JUnit and JavaFX frameworks
- applying object-oriented programming principles and SOLID software design principles in Java
- recognizing and applying design patterns to simplify software design
- git version control (branching, merging, and poll requests)
- coordinating and working within a team to develop software
- agile scrum methodologies (which are used by teams of professional software engineers today)
Bitmap Image Compressor
March 2021
This is one of my favourite projects because of its practicality. I programed a bitmap image compressor using Python. The main idea behind this application is recursion and trees.
To store an image in our program, we begin by spliting the image into four quadrants, and then we further split each of those quadrants recursively until we get down to single pixels. We can use a Quadtree (a tree data structure where each node has exactly four children) to store individual pixels as leafs in the tree.
To compress images we introduce something called a loss level which will be inputted by the user. Now when we are storing the image by splitting it into four quadrants, we can calculate the standard deviation and mean of the pixels inside of each quadrant. If the standard deviation is less than the user specified loss level, then we can treat the entire quadrant as a single pixel and its colour value will be given by the mean.

Before

After

Before

After
Meepo is You
February 2021
In this project I gained experience with applying object-oriented programming principles, reasoning with code not written by me, and working with the pygame and pytest frameworks.
Meepo is You is written in Python and has a nice graphical user interface (note the GUI was given to me, my task was to implement the game logic).
The player can move around the map using the keyboard. They can push blocks on the map to create and modify the rules of the game.

Phrase Puzzler
October 2020
In this project I was required to implement game functionality and logic for a word puzzle game in Python. It is a command-line interface game with three modes:
- One Player
- Player vs. Player
- Player vs. Computer (Easy and Hard)
The objective of the game is to guess a hidden word. On each turn, you can either:
- Guess a vowel (-1 point)
- Guess a consonant (+1 point)
- Guess the word
So very similar to Hangman, but to guess a vowel you need at least one point. You gain points by guessing consonants in the hidden word correctly. The player that determines the hidden word first wins.
